앞서 Spring Batch 시작하기에서 설명했던 대로 실행을 해보면 Bean만 생성했을 뿐인데, 자동으로 실행이 된다.
그 이유를 아래 내부 구조 그림으로 이해해보자
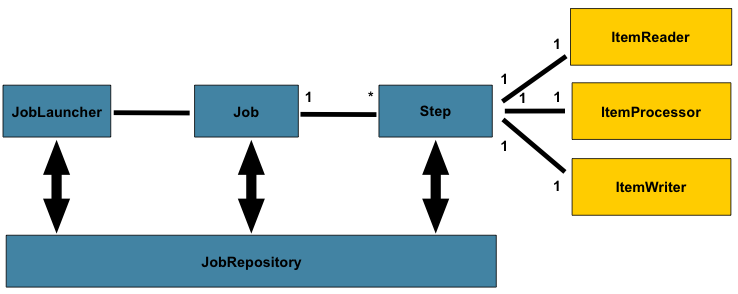
Spring Batch 공식 가이드 문서의 구조 이미지
Spring Batch는 Bean이 생성되면 JobLauncher 객체에 의해서 Job을 수행한다.
-
JobLauncher
-
Job
-
Step
JobRepository는 데이터베이스나 메모리에 스프링 배치가 실행될 수 있도록 메타데이터를 관리하는 클래스이다.
전반적인 데이터를 관리하기 위한 용도로 사용되는 클래스라고 이해하면 될 것 같다.
- Job은 JobLauncher에 의해 실행
- Job은 배치의 실행 단위를 의미
- Job은 N개의 Step을 실행할 수 있으며, 흐름(Flow)을 관리할 수 있음.
- ex. A Step을 실행 후, 조건에 따라 B Step 또는 C Step을 실행하도록 설정할 수 있다.
- Job의 세부 실행 단위이며, Job은 최소 1개 이상의 Step으로 구성
- Step의 실행 단위는 크게 2가지로 나뉨
- Task 기반: 하나의 작업 기반으로 실행
- 처리 대상이 한 번에 실행해도 컴퓨터 자원에 문제가 없을 때 사용.
- Chunk 기반: 하나의 큰 덩어리를 n개씩 나눠서 실행 (chunk = 덩어리 라는 뜻을 가짐)
- 10,000건의 데이터를 을 1,000건 씩 나눠서 처리한다면 Chunk
- 일반적으로 Task방식 보다 Chunk방식을 선호한다. 그 이유는 데이터를 묶어서 처리하기 때문에 대용량 데이터 처리에 적합하기 때문이다.
- ItemReader : 배치 처리 대상 객체를 읽어 ItemProcessor 또는 ItemWriter에게 전달
- ItemProcessor: input 객체를 output 객체로 filtering 또는 processing해 ItemWriter에게 전달
- ex) ItemReader에서 읽은 데이터를 수정 또는 ItemWriter 대상인지 filtering 한다.
- ItemProcessor는 optional하다. (있을 수도 있고 없을 수도 있다는 의미)
- ItemProcessor가 하는 일은 ItemReader 또는 ItemWriter가 대신할 수 있다.